Hi, this is Gergely with a special edition of the Pragmatic Engineer Newsletter. Each issue covers insights on Big Tech and startups from the perspective of senior engineers and engineering leaders. Today, we delve into one of the four topics from the latest AWS outage. Read more here. To receive articles like this in your inbox, subscribe here.
Monday was notably eventful: Signal was down, Slack and Zoom encountered issues, and many Amazon services were unavailable, affecting thousands of websites and apps worldwide. The root cause was a 14-hour AWS outage in the us-east-1 region.
Today, we’ll explore the cause of this disruption.
AWS provided regular updates throughout the incident. They released a thorough postmortem three days later, a significant improvement compared to the four-month wait following a similar event in 2023.
The most recent outage stemmed from a DNS failure in DynamoDB. DynamoDB is a durable, highly available serverless NoSQL database that assures 99.99% uptime with multi-availability zone replication. This makes it a reliable choice for data storage in various applications, including many AWS services. Despite its outstanding uptime performance, the outage left the dynamodb.us-east-1.amazonaws.com address with an empty DNS record, rendering DynamoDB services in that region inaccessible.
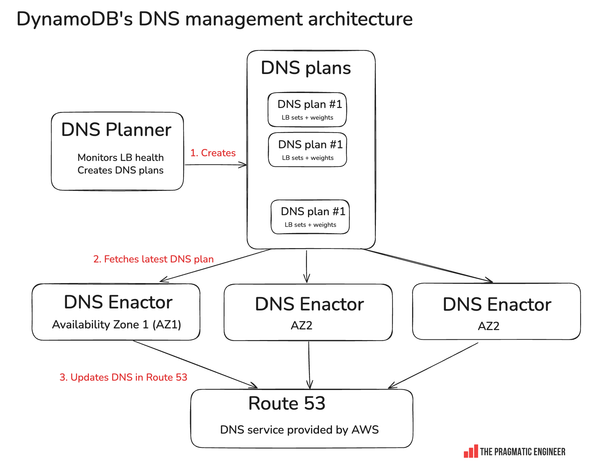
How DynamoDB DNS management works
Key points:
- DNS planner: Monitors load balancer health. When overloading occurs, new LBs are added; underutilization prompts removal. The planner creates DNS plans assigning weights for traffic distribution.
- DNS enactor: Updates routes in Route 53, with one operating per AZ for resilience. The us-east-1 region has three AZs, each with its own DNS enactor.
- Race conditions: With parallel DNS enactors, race conditions are expected. The system relies on eventual consistency for synchronization.
DynamoDB down for 3 hours
The outage was caused by a combination of independent events:
- High delays on DNS Enactor #1. One enactor experienced unusual delays in DNS updates.
- Increased DNS Planner activity. The DNS planner began generating new plans more frequently.
- Rapid processing by DNS Enactor #2. This enactor swiftly applied plans and removed older versions.
This sequence led to an inconsistent state, emptying the DNS record:
- DNS Enactor #1 used an outdated DNS plan. The enactor was slow, operating on an old plan.
- DNS Enactor #2’s cleanup check detected and deleted the old plan. Deleting the plan emptied the regional DNS entries, effectively wiping DynamoDB’s DNS record.
The downtime also affected multiple AWS services dependent on DynamoDB in us-east-1, though global tables allowed for some mitigation with delayed replication.
The postmortem could be missing crucial details:
- Reason for sluggishness in the DNS Enactor #1.
- Rationale behind DNS Enactor #2’s deletion of DNS records.
- Whether the magnitude of race conditions is deemed problematic and its frequency.
- Future strategies to address these vulnerabilities.
Amazon EC2 down for 12 additional hours
EC2 issues persisted post-DynamoDB recovery. Key considerations for EC2 operations:
- DropletWorkflow Manager (DWFM): Manages EC2 server resources, tracking server leases.
- Lease checks: Regular checks update server availability status.
Challenges from the DynamoDB outage:
1. Lease expirations caused by missed state checks. DWFM marked servers unavailable due to missing status updates.</p