Apple’s researchers have created a groundbreaking AI model that can reconstruct a 3D object from just one image while preserving consistent reflections, highlights, and various visual effects from multiple viewing perspectives. This progress is outlined in their paper titled “LiTo: Surface Light Field Tokenization.”
### A Bit of Context
The notion of latent space in machine learning has surged in popularity in recent years, especially with the advent of transformer-based AI models. Latent space pertains to the practice of compressing information into numerical forms and arranging these figures within a multi-dimensional framework, facilitating efficient distance and probability calculations.
For example, by altering mathematical representations of words, one can uncover relationships among them, such as transforming “king” into “queen” by adding and subtracting other representations.
This technique of encoding information as mathematical forms allows for quicker and less computationally demanding evaluations, relevant to a variety of data forms, including images.
### LiTo: Surface Light Field Tokenization
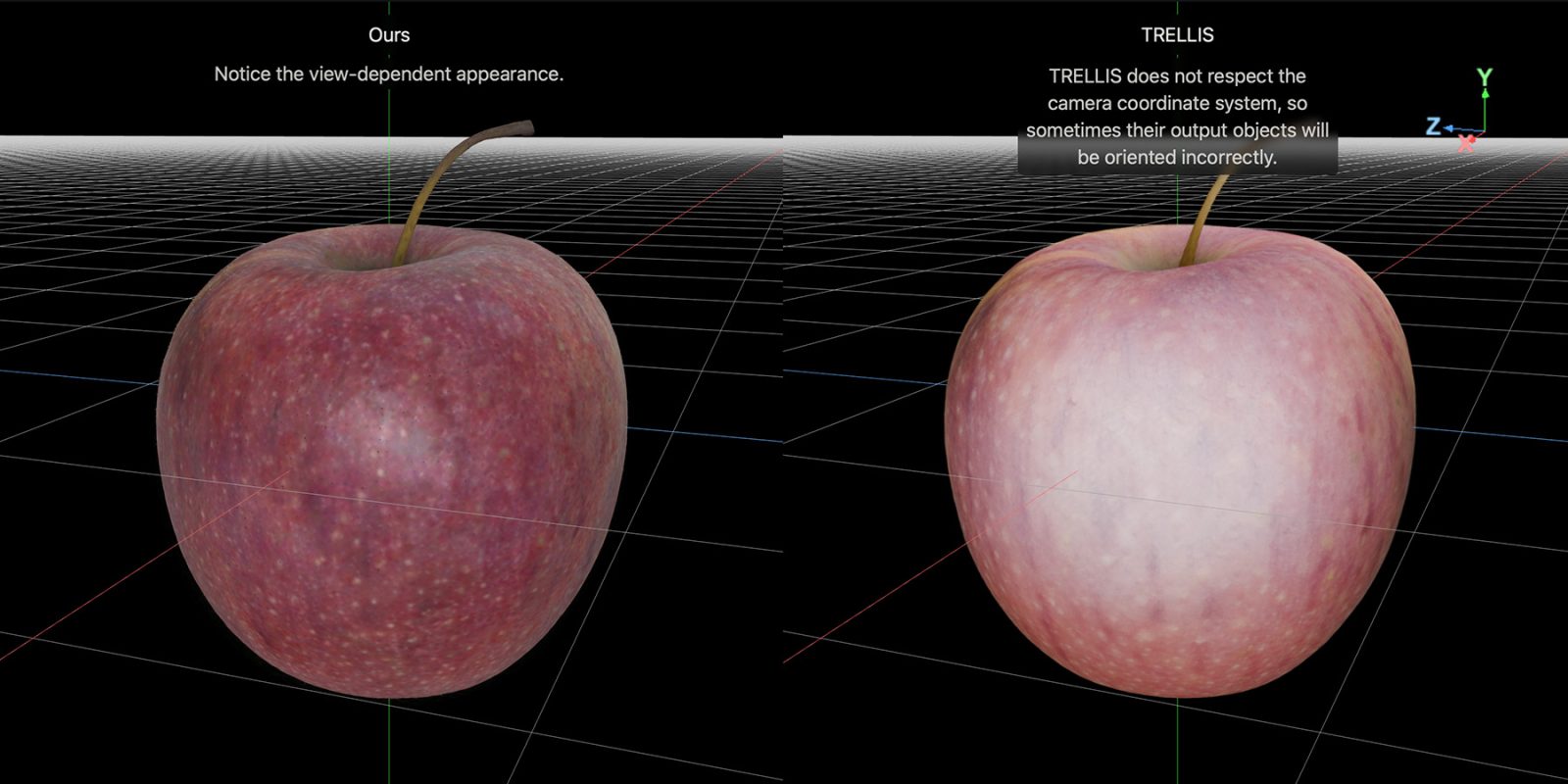
In their study, Apple introduces an innovative 3D latent representation that encompasses both object geometry and view-dependent appearance. This method allows for capturing how light interacts with an object from various angles, reflecting realistic phenomena such as specular highlights and Fresnel reflections.
The researchers point out that earlier techniques primarily concentrated on either 3D geometry reconstruction or view-independent appearance, restricting their capacity to illustrate realistic view-dependent effects. By employing RGB-depth images to sample a surface light field, their model consolidates subsamples into a concise set of latent vectors, enabling a cohesive representation of geometry and appearance.
### Training LiTo
To train the model, the researchers utilized thousands of objects rendered from 150 distinct angles and three different lighting conditions. Instead of employing all the data at once, the system randomly chose small subsets to form a latent representation. The decoder was then trained to recreate the entire object and its appearance from these subsets.
The training methodology involved understanding how the object’s geometry and appearance fluctuate with varying viewing angles. Ultimately, a separate model was developed to take a single image and forecast its corresponding latent representation, allowing the decoder to recreate the complete 3D object.
### Comparison with Other Models
Apple’s research provides comparisons between their LiTo model and another model known as TRELLIS. The project page encompasses interactive side-by-side comparisons, highlighting the proficiency of LiTo in reconstructing 3D objects from single images.
For more information and to check out the interactive comparisons, you can visit the [project page](https://apple.github.io/ml-lito/index.html#recon-comparison) and view the full study [here](https://arxiv.org/abs/2603.11047).